Go 白盒测试
Sep 16 2020
从待测函数开始
假设要写一些数学相关的代码,我们有一个 mymath 包,当前只有一个 sum.go,内容如下:
package mymath
// 计算从 1 到 n 的和
func Sum(n uint) uint {
var res uint
for i := uint(1); i <= n; i++ {
res += i
}
return res
}单元测试
Unit Test, 简称 UT
关注实现逻辑是否正确,是否能按照预期工作
UT 的覆盖率指标比较重要,最理想的情况是覆盖了待测试代码所有可能情况
第一版 UT
创建 sum_test.go 文件
文件名有规范,需要是待测 Go 文件原名 .go 前加 _test 后缀;测试文件和待测文件放在同一目录下
测试文件内容
package mymath
import "testing"
func TestSum0(t *testing.T) {
res := Sum(10)
if res != 55 {
t.Error("failed")
}
}
func TestSum1(t *testing.T) {
res := Sum(100)
if res != 5050 {
t.Error("failed")
}
}运行第一版 UT
进入 sum.go 和 sum_test.go 所在目录,执行如下命令
go test .会有类似如下回显
ok xxxxxx/mymath 0.114s这表示 TestSum0 和 TestSum1 两个用例都通过了测试
可以故意修改 Sum 函数实现,比如最后返回时加个 1,再执行测试会有类似如下回显:
--- FAIL: TestSum0 (0.00s)
sum_test.go:8: failed
--- FAIL: TestSum1 (0.00s)
sum_test.go:15: failed
FAIL
FAIL xxxxxx/mymath 0.086s
FAIL第二版 UT
TestSum0 和 TestSum1 的重复代码太多,可以抽取相同的部分,统一起来
func TestSum2(t *testing.T) {
type info struct {
input uint
expected uint
}
cases := []info{
{input: 10, expected: 55},
{input: 100, expected: 5050},
}
for _, c := range cases {
res := Sum(c.input)
if res != c.expected {
t.Errorf("failed. want: %d, got: %d\n", c.expected, res)
}
}
}这么写的好处是什么?
第三版 UT
info 结构体可以匿名化
func TestSum(t *testing.T) {
cases := []struct {
input uint
expected uint
}{
{input: 10, expected: 55},
{input: 100, expected: 5050},
}
for _, c := range cases {
res := Sum(c.input)
if res != c.expected {
t.Errorf("failed. want: %d, got: %d\n", c.expected, res)
}
}
}业界把这种写法称作表格驱动
可能是会以文件形式写个表格,再解析成 cases 切片来测试,每次只需向表格里加用例
实际开发,我们只需要向 cases 切片加用例即可,可以叫这种写法为数组驱动或切片驱动~
第四版 UT
第三版用例写法已经比较完美了,但有个小问题,如果测试失败了,是哪个用例失败了呢?
解决的方法也很简单,可以给匿名结构体加个 string 类型的字段 name,
for 循环时发现结果不符合预期打印当前用例的 name 即可区分
实际上 testing 包有更到位的封装,t.Run 函数就可以携带用例名称参数
func TestSum(t *testing.T) {
type args struct {
n uint
}
tests := []struct {
name string
args args
want uint
}{}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := Sum(tt.args.n); got != tt.want {
t.Errorf("Sum() = %v, want %v", got, tt.want)
}
})
}
}注意到标准模板的代码对函数入参也做了抽象,这在参数较多的时候比较好
对于我们的例子,不必定义 args 结构体
修改后的 UT 代码如下:
func TestSum(t *testing.T) {
tests := []struct {
name string
n uint
want uint
}{
{name: "n=10", n: 10, want: 55},
{name: "n=100", n: 100, want: 5050},
{name: "n=3", n: 3, want: 7},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := Sum(tt.n); got != tt.want {
t.Errorf("Sum() = %v, want %v", got, tt.want)
}
})
}
}运行第四版 UT
上边的三个用例,故意写错了第三个,运行看看会不会精确报错:
go test .--- FAIL: TestSum (0.00s)
--- FAIL: TestSum/n=3 (0.00s)
sum_test.go:18: Sum() = 6, want 7
FAIL
FAIL xxxxxx/mymath 0.087s
FAIL
PS xxxxxx\mymath>非常明确地打印出了出错的待测试函数,待测试用例以及实际运行结果和预期值
UT 覆盖率
要保证所有用例都通过,才能统计 UT 代码的覆盖率
修复上边错误的第三条用例,即把 want 值改成 6 后,执行:
go test . -cover预期会有类似如下回显:
ok xxxxxx/mymath (cached) coverage: 100.0% of statements对于我们的 Sum 函数,因为只有一个主分支,即使只有一个测试用例,覆盖率都会是 100%
基准测试
就是压力测试,着重考察代码的性能
如当前的 Sum 函数,时间复杂度 O(n),并不是一个太好的实现,我们写个基准测试测一下
func BenchmarkSum(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = Sum(10000)
}
}可以看到基准测试以“Benchmark”开头,后加待测试函数名,参数为 *testing.B 类型
go test -bench="BenchmarkSum"...
BenchmarkSum-12 443883 2667 ns/op
...意为做了 443883 次调用,每次耗时 2667 ns
重构 Sum
用等差数列前 n 项和公式优化 Sum 函数实现,将时间复杂度降低到 O(1):
func Sum(n uint) uint { return (1+n)*n/2 }重构后先做单元测试,保证重构后 Sum 按照预期工作
go test -run="TestSum" PASS ok xxxxxx/mymath 0.080s再看看现在的性能
go test -bench="BenchmarkSum" ... BenchmarkSum-12 1000000000 0.476 ns/op ...
示例测试
严格来说,这并不算测试,可以作为 Api 使用文档的一部分
举个例子,假如对标准库优先队列"container/heap" 的 Api 不太了解,就可以看标准库官方源码 container/heap 下的 example_intheap_test.go 和 example_pq_test.go, 如 example_intheap_test.go 后半部分代码:
...
// This example inserts several ints into an IntHeap, checks the minimum,
// and removes them in order of priority.
func Example_intHeap() {
h := &IntHeap{2, 1, 5}
heap.Init(h)
heap.Push(h, 3)
fmt.Printf("minimum: %d\n", (*h)[0])
for h.Len() > 0 {
fmt.Printf("%d ", heap.Pop(h))
}
// Output:
// minimum: 1
// 1 2 3 5
}注意到 代码后边的 Output 注释,并不是单纯的注释,而是预期输出,可以跑一下 Example_intHeap
xxx\src\container\heap> go test -run="Example_intHeap"
PASS
ok container/heap 0.080s如果实际运行输出结果与 output 注释里的不一致,则测试不通过
更进一步
go test 更多参数及用法,可用以下命令查看:
go help test go help testflagtesting.T 及 testing.B 更多 Api
查看标准库 testing 源码及测试代码
基准测试里的 b.N 到底是多少?怎么确定的?
查看标准库 testing 源码
代码有网络、数据库等依赖,怎么打桩测试
关于 rest 请求的,可以参考下一个问题;另外 github 上有不少 mock 库可参考学习
Go 长于 web 编程,标准库有没有好用的 rest 请求相关测试模块
net/http/httptest正是所求
Bit Set
有人问我是与非,说是与非 ——李宗盛《为你我受冷风吹》
13 Jun 2019
标准库里的数据结构
- array, slice, map 语言自带
- sync.Map 线程安全的 map
- container/list.List 双向链表
- container/heap 一棵树,每个节点都比子树所有节点小
- container/ring 循环链表
自定义数据结构
- queue 队列,提供一个 FIFO(先进先出)的序列
- stack 栈,提供一个 LIFO(后进先出)的序列
- set 就是我们高中数学学过的集合~
base 或 safe?
dsGo 提供 base 和 safe 两种版本的数据结构
base 版本的性能高于 safe 版
safe 版本是线程安全的Bit set
也叫 bit array,bit vector。
众猿媛所周知,我们用一个 bool 变量来存储一个 true 或 false 值
如果要存的数据量比较大呢?比如存储公司 180000 员工的性别
用一个 bool 数组的话,就需要 180000 字节的内存
换用 bit 来存储(假设 1 代表男,0 代表女)的话,显然需要的空间将变成 1/8
曾经的一道面试题
给定一个自然数 n,将它写成 2 的幂的和的形式 即写一个函数f,满足类似如下测试:
func f(n uint) string {...}
func main() {
testCases := []struct{
input uint
expect string
}{
{input:3, expect:"2^0+2^1"},
{input:8, expect:"2^3"},
{input:1026, expect:"2^1+2^10"},
{input:2019, expect:"2^0+2^1+2^5+2^6+2^7+2^8+2^9+2^10"},
}
for _, c := range testCases {
result := f(c.input)
if result != c.expect {
fmt.Printf("failed. input:%d, expected:%s, got:%s\n", c.input, c.expect, result)
}
}
}让我们用计算机的视角看问题
计算机眼中,数字 3 就是:
...|0|0|0|0|0|0|1|1| --2^0+2^1数字 1026 就是:
...|0|0|0|0|0|0|1|0|0|0|0|0|0|0|0|1|0| --2^1+2^10我们可以用一个[]byte 来实现 bit set; 一开始:
|0|0|0|0|0|0|0|0|, |0|0|0|0|0|0|0|0|, ...假设要将 bitset[8]置为 1,怎么做呢?
|0|0|0|0|0|0|0|0|, |1|0|0|0|0|0|0|0|, ...不妨将底层 byte 切片记为 b, 那么我们做得事情是:
b[1] = b[1] | (1 << 7)假设要将 bitset[2019]置为 0 呢?
先确定 2019 对应的 b 的元素 index: 2019 / 8 也就是 252
第几个 bit 呢? 2019 % 8 也就是 3
b[252] = b[252] & ^(1 << (7 - 3))我的实现
链式编程
httpclient,一个轮子
11 May 2019
常规调用
package main
import (
hc "github.com/zrcoder/httpclient"
)
func main() {
p := struct {
Age int
Name string
}{Age: 27, Name: "Tom"}
client := hc.New()
client.Post("http://127.0.0.1:8888/test")
client.Header("someKey", "someValue")
client.ContentType(hc.ContentTypeJson)
client.Body(p)
resp, body, err := client.Go()
// do something with resonse
}链式调用
package main
import (
hc "github.com/zrcoder/httpclient"
"net/http"
)
func main() {
p := struct {
Age int
Name string
}{Age: 27, Name: "Tom"}
hc.New().
Post("http://127.0.0.1:8888/test").
Header("some key", "some value").
ContentType(hc.ContentTypeJson).
Body(p).
Do(func(response *http.Response, body []byte, err error) {
// do something with response
})
}更多例子
- 以标准库 httptest 包起一个服务,实现对 Person 对象的增删改查
- 用我们的链式库做两次 Put 调用,增加 Tom 和 Joe
- Get 调用查询当前的 Person 列表
- Post 调用修改 Joe 的年龄
- 删除 Tom
- 再次 Get 调用查询当前的 Person 列表
详见单元测试文件 client_test.go 的
Example函数
Body()函数支持的参数
- string
- []byte
- 自定义的结构对象,无需 json 转换
httpclient 如何处理错误
- 用一个数组记录所有错误?
- 只保持第一个产生的错误?
我们用后者
重新设计 heap 包
22 Jun 2020
标准库 container/heap 包的设计比较特别,Api 并非面向对象的风格,
这和其他语言甚至 Go 自身的其他数据结构如 container/list 不一样官方当前 Api 初体验
简单起见,我们先假设要管理一些整形数字;要同时用到大顶堆和小顶堆。怎么写呢?
定义 需要先实现两个类型,MinHeap 和 MaxHeap,分别实现 heap.Interface 接口, 即 Len、Less、Swap、Push、Pop 五个方法:
// 小顶堆 type MinHeap []int func (h MinHeap) Len() int { return len(h) } func (h MinHeap) Less(i, j int) bool { return h[i] < h[j] } func (h MinHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] } func (h *MinHeap) Push(x interface{}) { *h = append(*h, x.(int)) } func (h *MinHeap) Pop() interface{} { x := (*h)[len(*h)-1] *h = (*h)[:len(*h)-1] return x }
官方当前 Api 初体验
// 大顶堆
type MaxHeap []int
func (h MaxHeap) Len() int { return len(h) }
func (h MaxHeap) Less(i, j int) bool { return h[i] > h[j] }
func (h MaxHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *MaxHeap) Push(x interface{}) { *h = append(*h, x.(int)) }
func (h *MaxHeap) Pop() interface{} {
x := (*h)[len(*h)-1]
*h = (*h)[:len(*h)-1]
return x
}这里已经有明显的代码坏味道,重复代码太多;可以通过该自定义 heap 增加函数类型属性 cmp 来解决,这里不细说,后边重新设计后有类似实现。
官方当前 Api 初体验
使用
nums := []int{2, 9, 10, 7, 4, 3} minHeap := &MinHeap{} maxHeap := &MaxHeap{} for _, v := range nums { heap.Push(minHeap, v) heap.Push(maxHeap, v) } fmt.Println(heap.Pop(minHeap)) fmt.Println(maxHeap[0])可以看到,没有 Peek 方法,直接取第 0 个元素即峰顶;push 和 pop 使用了 heap 包的 Push Pop 方法, 而不是直接这样:
minHeap.Push(5) maxHeap.Pop()综合看,步骤 1 里需要实现 heap.Interface 接口,并且步骤 2 使用的是 heap 包的 Push 和 Pop 方法,而不是类型本身的 Push 和 Pop 方法
分析修改 Api 设计
看起来标准库当前设计并不友好,尝试修改下,让 Api 更易用
使用者只需关注比较逻辑
堆底层是一个切片, heap.Interface 里要求的五个方法 Len、Less、Swap、Push、Pop, 有四个无需使用者关注,只有比较逻辑需要使用者确定 这里可以定义一个只包含 Less 方法(改名为 Cmp 更好)的接口让使用者实现, 或者直接给我们的结构体增加函数类型的 cmp 属性Push 和 Pop 直接按照堆实例的方法调用
基于上条分析,Push 和 Pop 就可以直接按照堆实例的方法调用,而不用弄成一个包方法
分析修改 Api 设计
我们需要提供一个这样的 Heap:
type Cmp func(i, j int) bool
type Any interface{}
type Heap interface {
InitWithCmp(cmp Cmp)
Get(i int) Any
Push(x Any)
Pop() Any
Peek() Any
}注意到有一些上面没有提到的方法,有的是为了方便使用,如 Peek、Len,有的是基于当前设计的实现需要。
分析修改 Api 设计
现在使用起来就是这样:
func main() {
nums := []int{2, 9, 10, 7, 4, 3}
minHeap := heap.NewWithCap(len(nums))
minHeap.InitWithCmp(func(i, j int) bool {
return minHeap.Get(i).(int) < minHeap.Get(j).(int)
})
maxHeap := heap.NewWithSlice(nil)
maxHeap.InitWithCmp(func(i, j int) bool {
return maxHeap.Get(i).(int) > maxHeap.Get(j).(int)
})
for _, v := range nums {
minHeap.Push(v)
maxHeap.Push(v)
}
fmt.Println(minHeap.Pop())
fmt.Println(maxHeap.Peek())
}先忽略 NewWithCap 和 NewWithSlice, 可以看到,使用者唯一需要确定的就是比较逻辑,即完成 InitWithCmp 方法就创建好了堆实例
分析修改 Api 设计
有两个实现方法
- 包装标准库已有 Api
- 从底层写起
分析修改 Api 设计
包装标准库已有 Api
func New() Heap { return NewWithCap(0) } func NewWithCap(cap int) Heap { return &heapImp{inner: &helper{slice: make([]Any, 0, cap)}} } func NewWithSlice(slice []Any) Heap { return &heapImp{inner: &helper{slice: slice}} } type heapImp struct { inner *helper } func (h *heapImp) InitWithCmp(cmp Cmp) { h.inner.cmp = cmp heap.Init(h.inner) }
分析修改 Api 设计
func (h *heapImp) Get(i int) Any {
return h.inner.slice[i]
}
func (h *heapImp) Len() int {
return h.inner.Len()
}
func (h *heapImp) Peek() Any {
return h.inner.slice[0]
}
func (h *heapImp) Push(x Any) {
heap.Push(h.inner, x)
}
func (h *heapImp) Pop() Any {
return heap.Pop(h.inner)
}分析修改 Api
heapImp 的关键属性 inner 就是包装了标准库
type helper struct {
slice []Any
cmp Cmp
}
func (h *helper) Len() int { return len(h.slice) }
func (h *helper) Less(i, j int) bool { return h.cmp(i, j) }
func (h *helper) Swap(i, j int) { h.slice[i], h.slice[j] = h.slice[j], h.slice[i] }
func (h *helper) Push(x interface{}) {
h.slice = append(h.slice, x)
}
func (h *helper) Pop() interface{} {
n := len(h.slice)
x := h.slice[n-1]
h.slice = h.slice[:n-1]
return x
}分析修改 Api 设计
从头实现
详见GitHub
参考标准库核心方法 up 和 down ,从头写heapImp 注意到还有些扩展 Api: Get用来获取指定索引元素,主要用在InitWithCmp方法中; Update 和 Remove 方法, 可用于更新或移除指定索引处的元素; IndexOf 用来获取指定元素在堆中的索引,获取索引后可继续调用Update 或 Remove方法。更多参考:
分治和回溯
8 Jul 2020
解决算法问题的乐趣
以LeetCode平台为例
- 问题聚焦,需求明确
- 测试完备,性能敏感
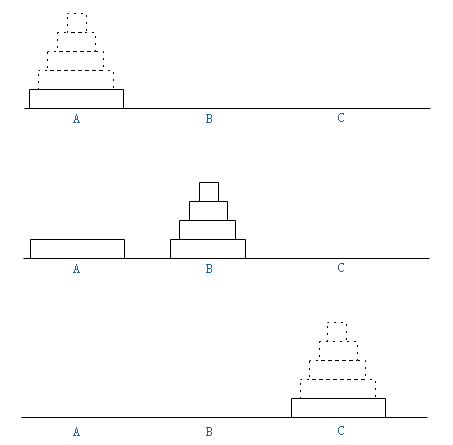
学生时代的际遇:汉诺塔问题
初中时代,同学游戏机里初遇:
求对于n个盘子,移动到最终位置需要的最少步数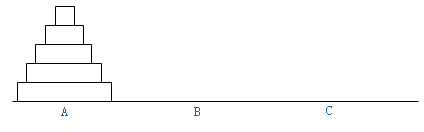
f(n)=2∗f(n−1)+1
func hanioSolutions(n int) int {
dp := 1
for i := 2; i <= n; i++ {
dp = 2*dp + 1
}
return dp
}高中时代,学习了数列的递推公式和通项公式
f(n)=2f(n−1)+1
f(n)+1=2[f(n−1)+1]
f(n)+1 是个等比数列, 首项是f(1)+1=2, 公比是2
f(n)+1=2n
f(n)=2n−1
时间复杂度由 o(n) 降为 O(1)
func hanioSolutions(n int) int {
return (1<<n) + 1
}分治:分而治之,化整为零
二分搜索、快排、归并排序、动态规划等
回溯:穷举尝试,有错就改
数组、链表、树、图、二维矩阵的DFS等
分治思想应用的例子
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,
而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。朴素实现,排序后再求解,时间复杂度 O(nlgn),空间复杂度 O(1)
func findKthLargest(nums []int, k int) int {
sort.Sort(sort.Reverse(sort.IntSlice(nums)))
return nums[k-1]
}借助堆的解法
借助一个小顶堆,将nums里的元素一一入堆,但需要保持堆的大小最多为k,如果超出k,需要把堆顶元素出堆
func findKthLargest(nums []int, k int) int {
h := &IntHeap{}
for _, v := range nums {
heap.Push(h, v)
if h.Len() > k {
_ = heap.Pop(h)
}
}
return (*h)[0]
}时间复杂度O(nlgk),空间复杂度O(k);并不比朴素实现快多少
IntHeap 实现略,借助标注库
container/heap即可
快速选择算法
参照快排的思路,可以不必完全排完序
func findKthLargest(nums []int, k int) int {
if k < 1 || k > len(nums) {
return 0
}
quickSelect(nums, 0, len(nums)-1, k)
return nums[k-1]
}
func quickSelect(nums []int, left, right, k int) {
if left == right { // 递归结束条件:区间里仅有一个元素
return
}
pivotIndex := partition(nums, left, right)
if pivotIndex+1 == k {
return
}
if pivotIndex+1 > k {
quickSelect(nums, left, pivotIndex-1, k)
} else {
quickSelect(nums, pivotIndex+1, right, k)
}
}// 随机选择基准元素,大于基准的放在左侧,小于基准的放在右侧
// 返回最终基准元素的索引
func partition(nums []int, left, right int) int {
pivotIndex := left + rand.Intn(right-left+1)
pivot := nums[pivotIndex]
nums[right], nums[pivotIndex] = nums[pivotIndex], nums[right] // 1. 先把基准元放到最后
storeIndex := left
for i := left; i < right; i++ { // 2. 所有不小于基准元的元素放到左侧
if nums[i] >= pivot {
nums[storeIndex], nums[i] = nums[i], nums[storeIndex]
storeIndex++
}
}
nums[storeIndex], nums[right] = nums[right], nums[storeIndex] // 3. 基准元放到最终位置
return storeIndex
}时间复杂度 : 平均情况 O(N),最坏情况 O(N^2)。空间复杂度 : O(lgn),栈空间大小。
《算法导论》 9.2 期望为线性的选择算法
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
示例:
输入:
[
1->4->5,
1->3->4,
2->6
]
输出: 1->1->2->3->4->4->5->6这里只涉及到“治”,也就是合并,没有涉及"分“;其实可以考虑该问题的全貌:
有一个比较大的链表,需要对其排序
1. 可以先分割成n个小链表,并开辟n个协程对每个小链表排序
2. 最后合并这些小链表,并保持最终大链表有序首先实现将两个链表合并的 merge 函数
func merge(l1, l2 *ListNode) *ListNode {
dummy := new(ListNode)
for p := dummy; l1 != nil || l2 != nil; p = p.Next {
if l1 != nil && l2 != nil && l1.Val < l2.Val || l2 == nil {
p.Next = l1
l1 = l1.Next
} else {
p.Next = l2
l2 = l2.Next
}
}
l1, dummy.Next = dummy.Next, nil
return l1
}主体代码-实现 1:
func mergeKLists(lists []*ListNode) *ListNode {
var r *ListNode
for _, v := range lists {
r = merge(r, v)
}
return r
}合并并不均衡,考虑如下情形:
子链表1: 1 -> 5 -> 8
子链表2: 2 -> 6 -> 7
子链表3: 3 -> 9
子链表4: 4 -> 7 -> 8 -> 10
...按照当前的实现,会先合并子链表 1 和 2,长度变成 6;再和子链表 3 合并,长度变成 8;再和子链表 4 合并,长度变成 4;…
到后边会发现要合并的两个链表,长度非常不均衡,第一个非常长,第二个比较短
优化合并过程:
先两两合并子链表:1和2合并成链表x,2和4合并成链表y,...;再继续两两合并:x和y合并成链表a ...
以上合并方法同数组的归并排序合并方法,能有效优化合并时间
func mergeKLists(lists []*ListNode) *ListNode {
n := len(lists)
if n == 0 {
return nil
}
for interval := 1; interval < n; interval *= 2 {
for i := 0; i+interval < n; i += interval * 2 {
lists[i] = merge(lists[i], lists[i+interval])
}
}
return lists[0]
}分治:动态规划
如前边讨论到的汉诺塔问题递推公式,再如:面试题 08.01. 三步问题
有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。
实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要对结果模1000000007。
示例1:
输入:n = 3
输出:4
说明: 有四种走法
示例2:
输入:n = 5
输出:13
提示:
n范围在[1, 1000000]之间经典 dp 问题
// 假设 dp(n)表示到达第 n 个阶梯可能的方式数;
// 考虑倒数第二步:可以在第 n-1、n-2、n-3 这 3 个台阶上,然后一步就可以到达终点
// 所以 dp(n) = dp(n-1) + dp(n-2) + dp(n-3)
// 初始状态容易得到:dp(1), dp(2), dp(3) = 1, 2, 4
func waysToStep(n int) int {
if n == 1 {
return 1
}
if n == 2 {
return 2
}
if n == 3 {
return 4
}
dp1, dp2, dp3 := 1, 2, 4
for i := 4; i <= n; i++ {
dp1, dp2, dp3 = dp2, dp3, (dp1+dp2+dp3)%1000000007
}
return dp3
}回溯
穷举尝试,有错就改
一般具体实现为深度优先搜索,可应用到数组、链表、树、图、二维矩阵等多种数据结构相关的问题 // 回溯算法的框架
result = []
func backtrack(选择列表,路径):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(选择列表,路径)
撤销选择回溯函数的几种写法
回溯算法有一点和二分搜索很像:思想很简单,细节是魔鬼
设计一种算法,打印n对括号的所有合法的组合。
说明:解集不能包含重复的子集。
例如,给出 n = 3,生成结果为:
[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]写法一(框架):
func generateParenthesis(n int) []string {
result := make([]string, 0)
curr := make([]byte, 0, 2*n) // 记录当前构建的一个可能串
left, right := 0, 0 // 记录当前构建的串里左右括号的个数
// 回溯函数没有入参,也没有返回值
var backtrace func()
// 结果中已经出现left个左括号,right个右括号
backtrace = func() {
// ...
}
backtrace()
return result
}写法一(backtrace实现):
backtrace = func() {
if left > n || right > left { // 递归结束条件 1
return
}
if len(curr) == cap(curr) { // 等价于: left == right == n; 递归结束条件 2
result = append(result, string(curr))
return
}
// 尝试追加一个左括号
left++
curr = append(curr, '(')
backtrace()
// 回溯
left--
curr = curr[:len(curr)-1]
// 尝试追加一个右括号
right++
curr = append(curr, ')')
backtrace()
// 回溯
right--
curr = curr[:len(curr)-1]
}写法二:
将 left、right 作为参数,这样可以减少回溯代码
func generateParenthesis(n int) []string {
// ...
var backtrace func(int, int)
backtrace = func(left, right int) {
if left > n || right > left {
return
}
if len(curr) == cap(curr) {
result = append(result, string(curr))
return
}
curr = append(curr, '(')
backtrace(left+1, right)
curr = curr[:len(curr)-1]
curr = append(curr, ')')
backtrace(left, right+1)
curr = curr[:len(curr)-1]
}
backtrace(0, 0)
return result
}写法三:
left,right,cur 都可以作为参数传递
func generateParenthesis(n int) []string {
result := make([]string, 0)
var backtrace func(left, right int, curr []byte) []string
backtrace = func(left, right int, curr []byte) []string {
if left > n || right > left { // 递归结束条件1
return result
}
if len(curr) == 2*n {
result = append(result, string(curr))
return result
}
// 尝试追加一个左括号
backtrace(left+1, right, append(curr, '('))
// 尝试追加一个右括号
backtrace(left, right+1, append(curr, ')'))
return result
}
return backtrace(0, 0, nil)
}写法四:
result 作为回溯函数的返回值
func generateParenthesis(n int) []string {
result := make([]string, 0)
var backtrace func(int, int, string) []string
backtrace = func(left, right int, curr string) []string {
if left > n || right > left {
return result
}
if len(curr) == 2*n {
result = append(result, curr)
return result
}
backtrace(left+1, right, curr+"(") // 尝试追加一个左括号
backtrace(left, right+1, curr+")") // 尝试追加一个右括号
return result
}
return backtrace(0, 0, "")
}这个问题写成写法四意义不大;在记忆化搜索优化回溯过程的场景中有意义,比如下边机器人的例子。
回溯的优化
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?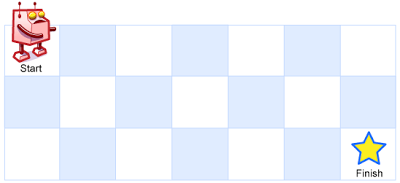
网格中的障碍物和空位置分别用 1 和 0 来表示。
说明:m 和 n 的值均不超过 100。
示例 1:
输入:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
输出: 2
解释:
3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右我们先尝试直接递归回溯
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
if len(obstacleGrid) == 0 || len(obstacleGrid[0]) == 0 {
return 0
}
m, n := len(obstacleGrid), len(obstacleGrid[0])
if obstacleGrid[0][0] == 1 || obstacleGrid[m-1][n-1] == 1 {
return 0
}
var dfs func(r, c int) int // dfs(r, c)表示从位置(r,c)到达终点可行的方法数
dfs = func(r, c int) int {
if r >= m || c >= n || obstacleGrid[r][c] != 0 {
return 0
}
if r == m-1 && c == n-1 {
return 1
}
return dfs(r+1, c) + dfs(r, c+1)
}
return dfs(0, 0)
}时间复杂度 O(2m+n), 空间复杂度 O(m+n),主要为递归栈的空间
优化思路一:给递归函数加上备忘录,来避免重复的计算
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
// ...
memo := make([][]int, m)
for i := range memo {
memo[i] = make([]int, n)
for j := range memo[i] {
memo[i][j] = -1
}
}
var dfs func(r, c int) int
dfs = func(r, c int) int {
// ...
if memo[r][c] != -1 {
return memo[r][c]
}
memo[r][c] = dfs(r+1, c) + dfs(r, c+1)
return memo[r][c]
}
return dfs(0, 0)
}给递归加上备忘录的做法也叫记忆化搜索,是对自顶向下的递归时间上的一个优化,时空复杂度都变成了 O(mn)
还可以自底向上用动态规划的方法来解决
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
// 边界处理代码略
m, n := len(obstacleGrid), len(obstacleGrid[0])
dp := [101][101]int{}
for r := 0; r < m; r++ {
for c := 0; c < n; c++ {
if obstacleGrid[r][c] == 1 {
continue
}
if r == 0 && c == 0 {
dp[r+1][c+1] = 1
} else {
dp[r+1][c+1] = dp[r][c+1] + dp[r+1][c]
}
}
}
return dp[m][n]
}小结
- 分治:分而治之,化整为零
- 回溯:穷举尝试,有错就改
分治思想应用的例子:
快排、归并排序、动态规划等
回溯思想应用的例子:
数组、链表、树、图、二维矩阵的DFS等
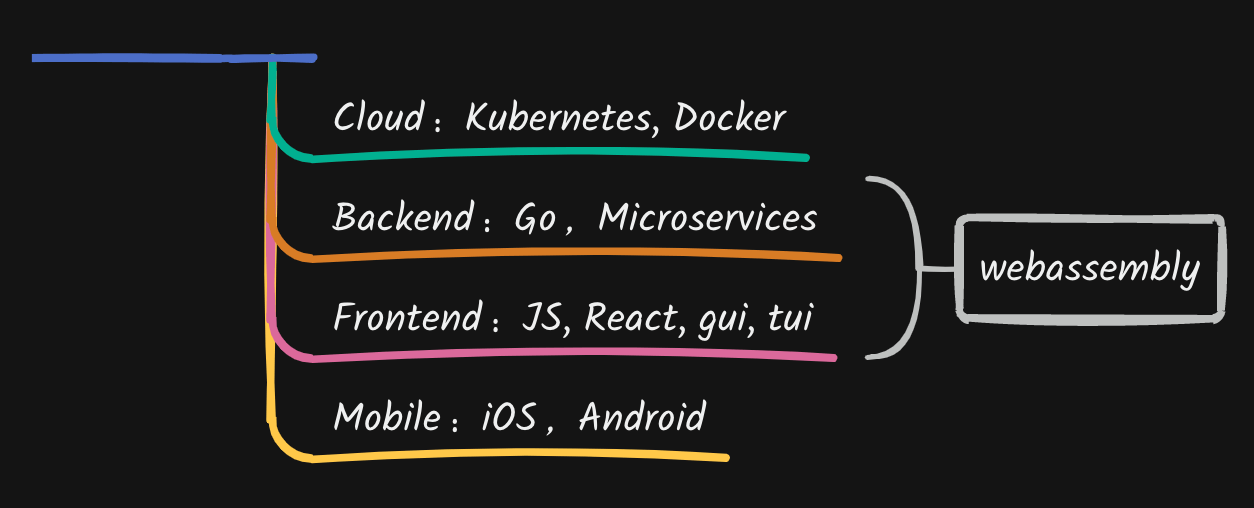
前端 ⇠⇢ 后端
用 webassymbly 统一前后端
func (idx *index) Render() app.UI {
return app.Div().Style("overflow", "hidden").Body(
// ...
app.Button().
ID("run-button").
Class("run-button").
OnClick(goButtonAction)
Text("GO"),
)
}func goButtonAction(ctx app.Context, e app.Event) {
root := app.Window()
code := root.Get("GetCode").Invoke().String()
imgData, err := pkg.Run(width, height, code)
// ...
root.Get(pictureAreaID).Set("src", imgData)
}